LLM Inference Optimization: 2026 Update
TL;DR: Since the initial overview in 2024, the “bottleneck war” has moved from simple KV cache management to architectural revolutions like Multi-Head Latent Attention (MLA) and hardware-native 4-bit floating point (FP4) on Blackwell GPUs.
Estimated reading time: 12 mins
This post serves as a direct update to my 2024 article on Large Transformer Model inference. While the original discussion established the foundations of I/O awareness and memory fragmentation, the industry has since moved toward a vertically integrated stack where model architecture and hardware work in unison. Below is a high-level summary contrasting the foundational techniques with the breakthroughs that define the 2026 landscape.
- Updated Summary Table
- Overview: The 2026 Landscape
- New Algorithmic Optimization
- System and Hardware Breakthroughs
- References
Updated Summary Table
| Technique | Phase Optimized | Primary Benefit | Applications / Frameworks |
|---|---|---|---|
| FOUNDATIONS (until 2024) | |||
| Quantization (AWQ1 / SmoothQuant2) | Both | Reduced VRAM | TensorRT-LLM3, vLLM4, BitsAndBytes |
| vLLM (PagedAttention4) | Decode | Solves Fragmentation | Industry Standard (vLLM, TGI, Ray Serve5) |
| GQA6 / MQA7 | Decode | Smaller KV Cache | Llama 2/38, Mistral 7B9, Falcon 40B10 |
| FlashAttention-1, 2, 311 | Prefill | IO-Awareness & Asynchrony | Native in PyTorch12, JAX13, CUDA kernels14 |
| Speculative Decoding (Draft-Target)15 | Decode | Lower Latency | T5-XXL15, Early GPT-4 Serving 16 |
| NEW FRONTIERS (2025 & 2026) | |||
| MLA (Latent Attention)17 | Decode | 4-6x KV Cache reduction | DeepSeek-V317, SGLang18, Qwen-Reasoning |
| MTP / Self-Speculation17 | Decode | Native generation speed | DeepSeek-V3, GPT-4o / GPT-519, Qwen320 |
| FP4 (NVFP4)21 | Both | 2-4x Throughput | Llama 422, FLUX.123, Blackwell GPUs |
| RadixAttention24 | Prefill | Instant Prefix Reuse | SGLang, vLLM (Prefix Caching)25, Snowflake26 |
| P-EAGLE27 | Decode | Parallel Drafting | vLLM, TensorRT-LLM, Qwen3-Coder27 |
Overview: The 2026 Landscape
In late 2024, the focus was on squeezing efficiency out of standard Transformers using techniques like GQA 6 and vLLM 4. In 2026, we have entered the era of Inference-Aware Architectures. Models are now designed during the pre-training phase to be inherently optimized for low-precision hardware and massive context windows.
New Algorithmic Optimization
Multi-Head Latent Attention (MLA)
Popularized by the DeepSeek-V3 series 17, MLA is the spiritual successor to Grouped-Query Attention (GQA). While GQA reduced the number of heads to save memory, MLA uses low-rank joint compression to “squeeze” Key and Value vectors into a tiny latent vector.
- Impact: It reduces the KV cache memory footprint by 4–6x compared to GQA.
- Adoption: Beyond DeepSeek, this architectural shift is seen in the Qwen-Reasoning models and is a core optimization supported in the SGLang inference engine 18.
Multi-Token Prediction (MTP) & Self-Speculation
Moving beyond standard “Next Token Prediction,” 2025/2026 models are increasingly trained with MTP heads. The model is trained to predict $k$ future tokens in parallel. This enables Self-Speculation, where the model drafts its own future tokens in a single forward pass, removing the need for a separate, smaller “draft model” previously required for speculative decoding 15.
- Usage: This is a defining feature of the DeepSeek-V3 and Qwen3 families 20. Evidence suggests that GPT-4o and GPT-5 transitioned to native multi-token prediction heads to achieve the high throughput observed in production, eliminating the I/O overhead of separate draft models 1928.
System and Hardware Breakthroughs
FP4 & NVFP4 (NVIDIA Blackwell)
With the rollout of the Blackwell architecture 21, FP4 (4-bit Floating Point) has replaced INT8/INT4 as the gold standard for high-speed inference. Unlike INT4, the NVFP4 format handles the dynamic range of activations much better, leading to negligible accuracy degradation. This provides a 2x–4x throughput boost over FP8/FP16.
- Ecosystem: Llama 4 22 and the FLUX.1 image generation family 23 are among the first to be distributed with native FP4 weights for Blackwell-based clusters.
RadixAttention & Prefix Caching
While vLLM solved physical memory fragmentation, RadixAttention (pioneered in SGLang 24) addresses the “redundant prefill” problem.
- Mechanism: It treats the KV cache as a Radix Tree. If multiple queries share a common system prompt or document, the engine “hits” the cache and skips the prefill phase entirely.
- Impact: This has been adopted as “Prefix Caching” in vLLM 25 and is extensively used by companies like Snowflake 26 and Anyscale to optimize TTFT for long-context RAG pipelines.
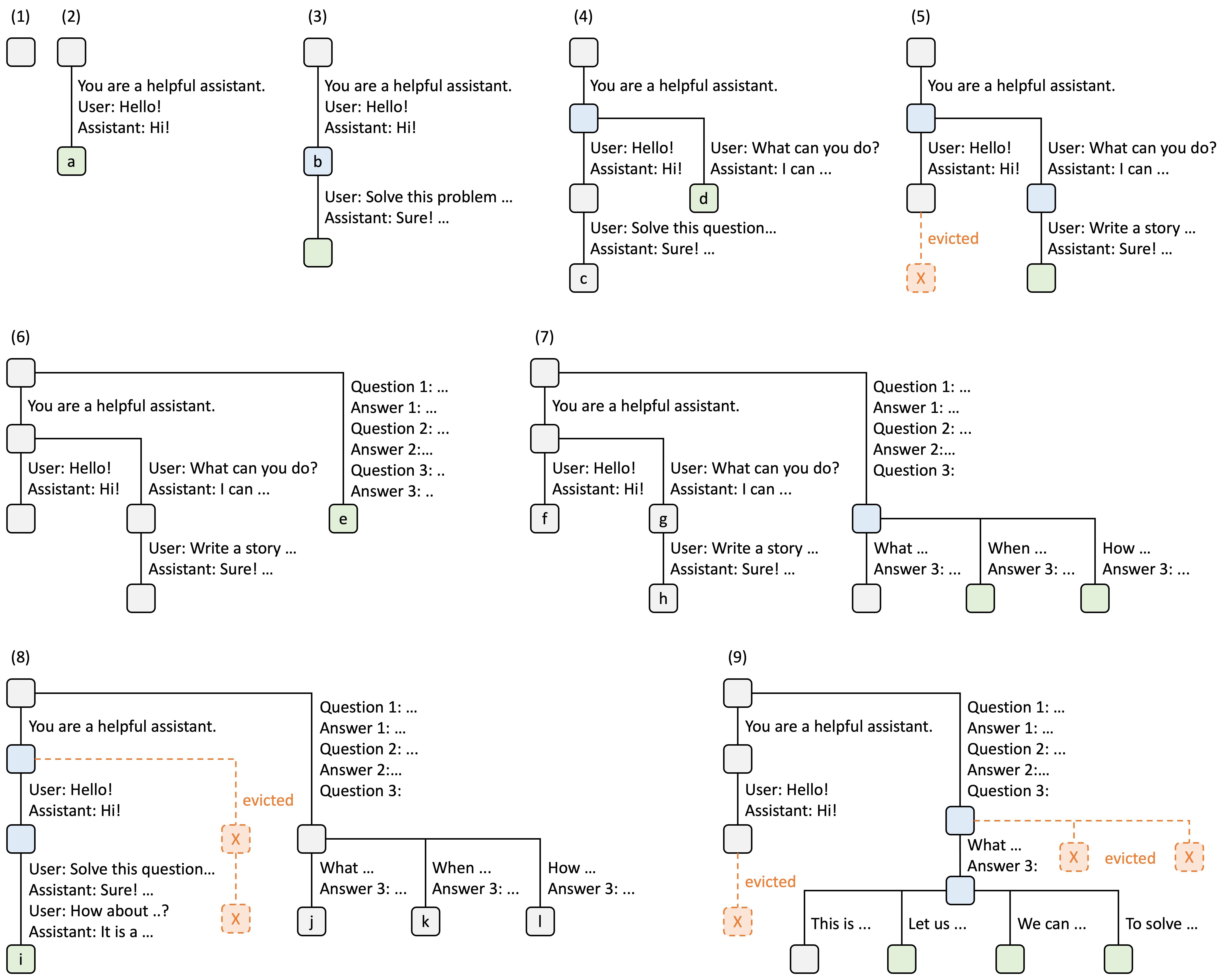
Figure 1: RadixAttention tree structure for efficient prefix reuse
Parallel Speculative Decoding (P-EAGLE)
Standard speculative decoding was often bottlenecked by sequential verification. P-EAGLE 27 allows the drafter model to generate a tree of possible future tokens in a single parallel step, pushing generational speedups from 2x up to 3.5x in high-concurrency environments.
- Serving: Now a staple in vLLM and TensorRT-LLM v1.0, especially for coding models like Qwen3-Coder 27 and GPT-OSS 29 where structured syntax makes parallel drafting highly effective.
References
-
Lin, Ji, et al. “AWQ: Activation-aware Weight Quantization for LLM Compression.” (2024). ↩
-
Xiao, Guangxuan, et al. “SmoothQuant: Accurate and Efficient Post-Training Quantization for LLMs.” (2023). ↩
-
NVIDIA. “Optimizing LLM Inference Performance with NVIDIA TensorRT-LLM.” (2024). ↩
-
Kwon, Woosuk, et al. “vLLM: Efficient Memory Management for LLM Serving.” (2023). ↩ ↩2 ↩3
-
Anyscale. “Scaling LLM Workloads with Ray Serve and vLLM.” (2024). ↩
-
Ainslie, Joshua, et al. “GQA: Training generalized multi-query transformer models.” (2023). ↩ ↩2
-
Shazeer, Noam. “Fast transformer decoding: One write-head is all you need.” (2019). ↩
-
Dubey, Abhimanyu, et al. “The Llama 3 Herd of Models.” (2024). ↩
-
Jiang, Albert Q., et al. “Mistral 7B.” (2023). ↩
-
Almazrouei, Ebtesam, et al. “The Falcon Series of Language Models.” (2023). ↩
-
Shah, Jay, et al. “FlashAttention-3: Fast and accurate attention with asynchrony.” (2024). ↩
-
PyTorch Foundation. “PyTorch 2.2: FlashAttention-v2 integration.” (2024). ↩
-
nshepperd. “JAX bindings for Flash Attention v2.” (2024). ↩
-
Dao, Tri, et al. “Flashattention: Fast and memory-efficient exact attention.” (2022). ↩
-
Leviathan, Yaniv, et al. “Fast inference from transformers via speculative decoding.” (2023). ↩ ↩2 ↩3
-
Artificial Analysis. “GPT-4o API Provider Benchmarking & Analysis.” (2024). ↩
-
DeepSeek-AI. “DeepSeek-V3 Technical Report.” (2025). ↩ ↩2 ↩3 ↩4
-
SGLang Project. “DeepSeek-V3 Support in SGLang.” (2025). ↩ ↩2
-
OpenAI. “Introducing GPT-5.4 mini and nano.” (2026). ↩ ↩2
-
Alibaba Group. “Alibaba Open-Sources Qwen3.5.” (2026). ↩ ↩2
-
NVIDIA. “3 Ways NVFP4 Accelerates AI Training and Inference.” (2026). ↩ ↩2
-
Wikipedia. “Llama (Language Model): Llama 4 Release.” (2025). ↩ ↩2
-
NVIDIA Blog. “Scaling NVFP4 Inference for FLUX.1 on NVIDIA Blackwell GPUs.” (2026). ↩ ↩2
-
LMSYS. “SGLang: Efficient Execution of Structured Language Model Programs.” (2024). ↩ ↩2
-
vLLM Project. “Automatic Prefix Caching Design.” (2026). ↩ ↩2
-
Agarwal et al. “From Prefix Cache to Fusion RAG Cache.” (2026). ↩ ↩2
-
AWS Machine Learning Blog. “P-EAGLE: Faster LLM inference with Parallel Speculative Decoding.” (2026). ↩ ↩2 ↩3 ↩4
-
Xu, Jiawei, et al. “A Comprehensive Survey on Large Language Models: From Pre-training to Autonomous Agents.” (2025). ↩
-
Hugging Face Blog. “GPT-OSS Model Evaluation.” (2025). ↩