vLLM - Revisit
In the world of Large Language Model (LLM) inference, the primary bottleneck isn’t just compute—it’s memory management. Specifically, the management of the Key-Value (KV) Cache. vLLM has emerged as the industry standard by borrowing a classic concept from Operating Systems: Virtual Memory 1.
1. The Core Innovation: PagedAttention
Traditional inference engines allocate KV cache in large, contiguous blocks. Because we don’t know the output length in advance, systems “over-reserve” space, leading to Internal Fragmentation (wasted space within a sequence) and External Fragmentation.
PagedAttention solves this by partitioning the KV cache into small, fixed-size Physical Blocks. A Block Table maps these logical sequences to physical locations, allowing memory to be allocated on-demand. The following animation 2 illustrates this mapping process.
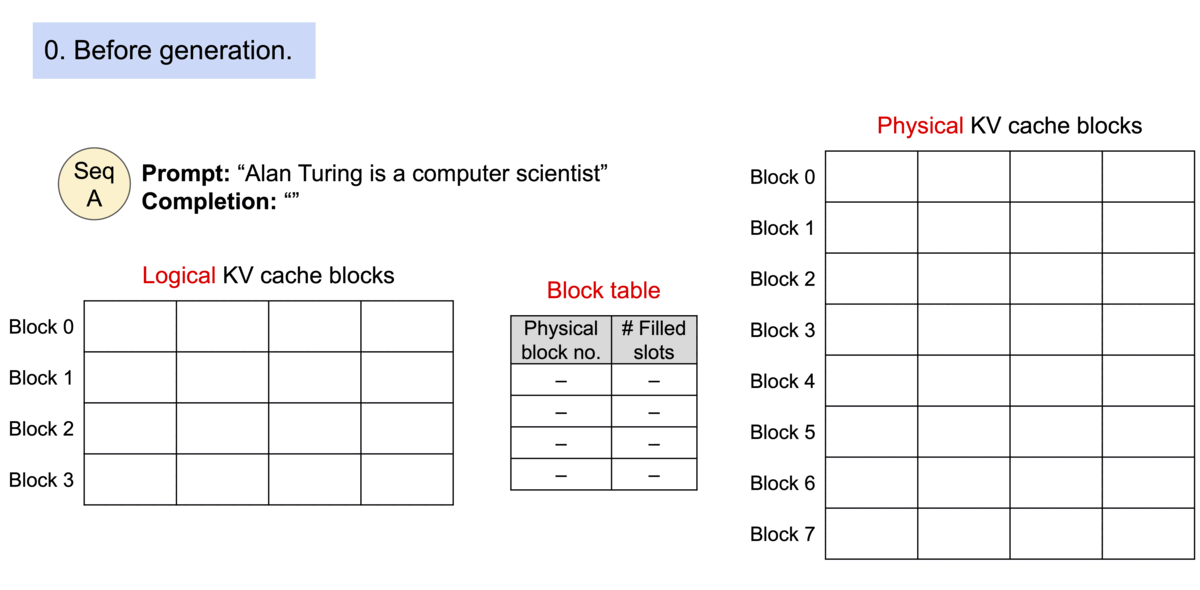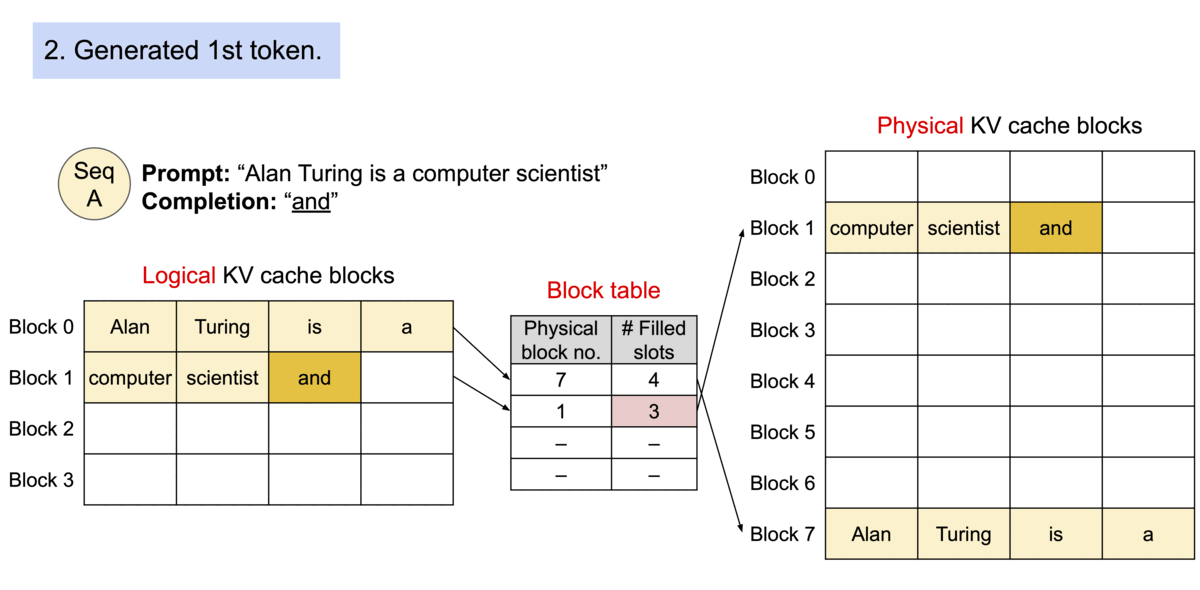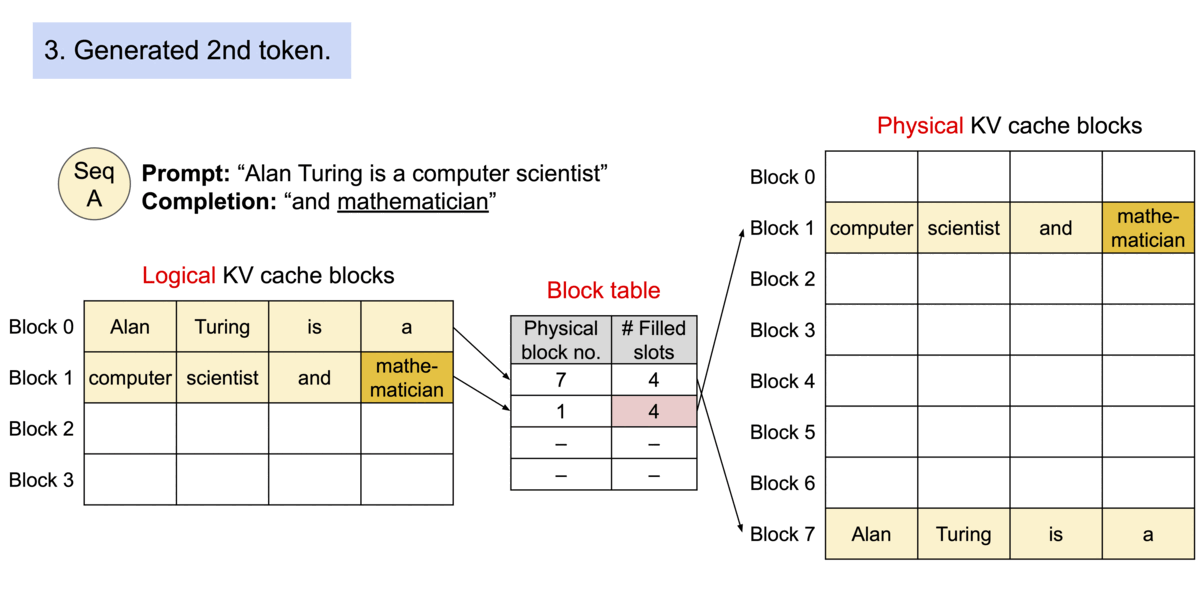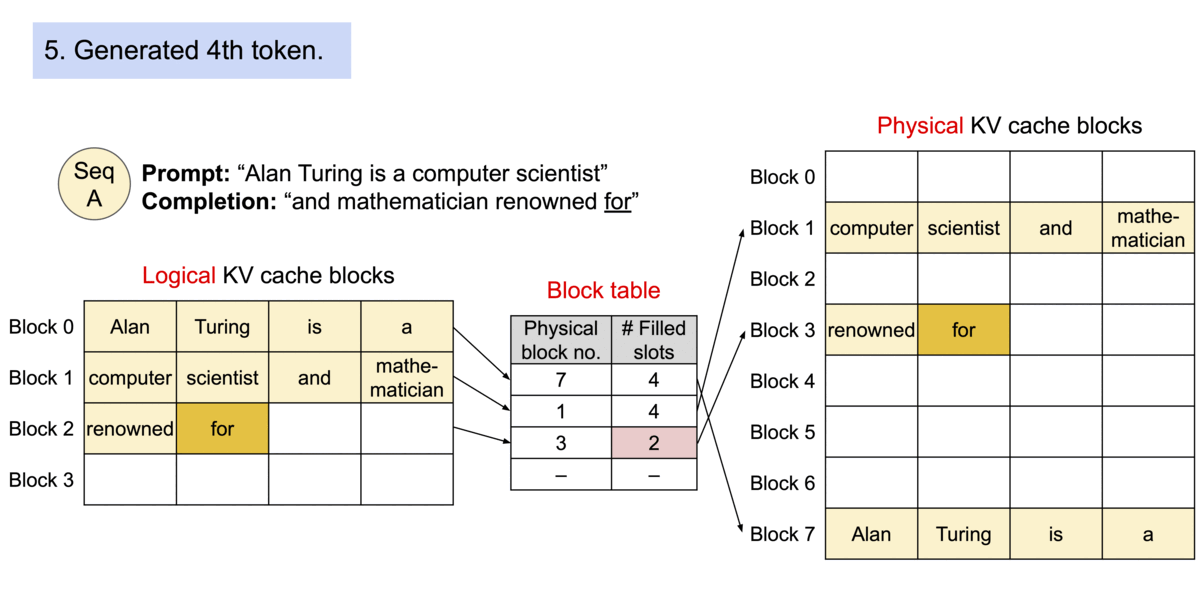
Figure 1: PagedAttention maps contiguous logical blocks to non-contiguous physical blocks, eliminating external fragmentation.
2. The Impact: Efficiency, Throughput, and Scaling
By decoupling the logical view from physical memory, vLLM transforms both the raw performance of the GPU and the way applications handle complex decoding.
Core Performance Gains: Memory and Throughput
- Near-Optimal Memory Usage: Research indicates that traditional systems typically waste 60% to 80% of GPU memory due to static over-reservation 1. vLLM reduces this waste to under 4%, effectively doubling or tripling the number of concurrent requests a single GPU can handle.
- Continuous Batching: Traditional batching waits for the entire batch to finish. vLLM uses Iteration-level Scheduling, checking for completed sequences after every single token. Completed requests are immediately evicted, and new ones are inserted, ensuring the GPU is never idle.
Operational Parallelism and Memory Sharing
Beyond raw speed, PagedAttention enables complex sharing patterns 2 previously too memory-intensive for production use.
- Intra-Request Parallelism (Parallel Sampling): When one request asks for multiple outputs (e.g.,
n=5), vLLM stores the prompt’s KV cache exactly once. All generated sequences point back to these same physical blocks, branching only when they begin to generate unique tokens.
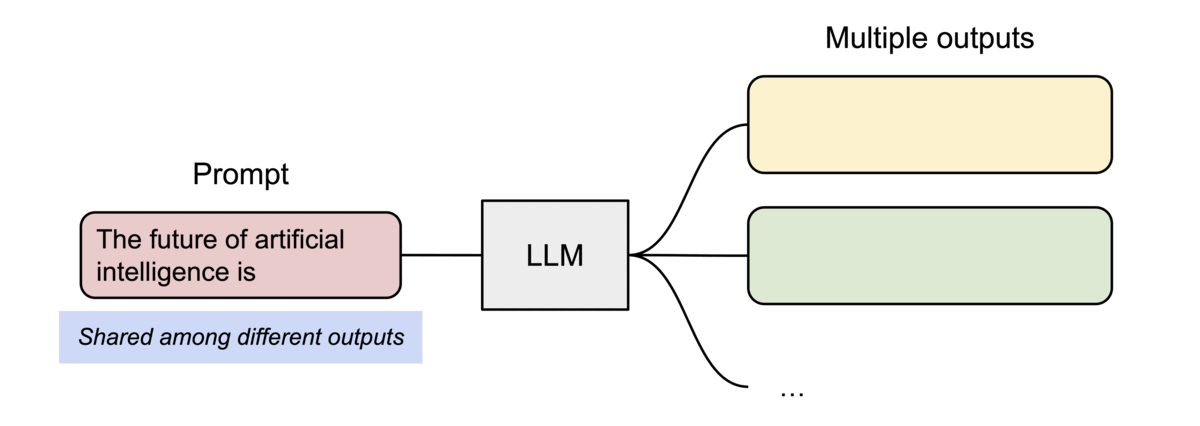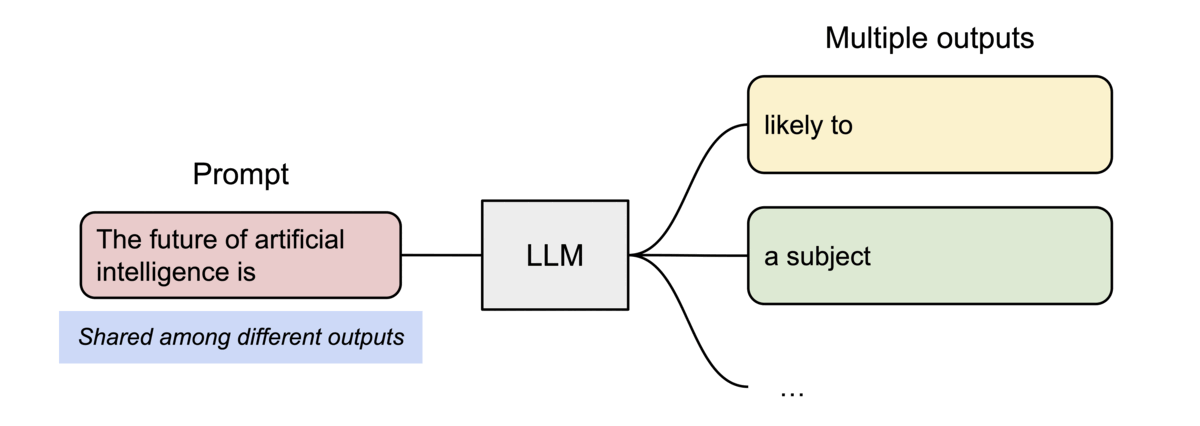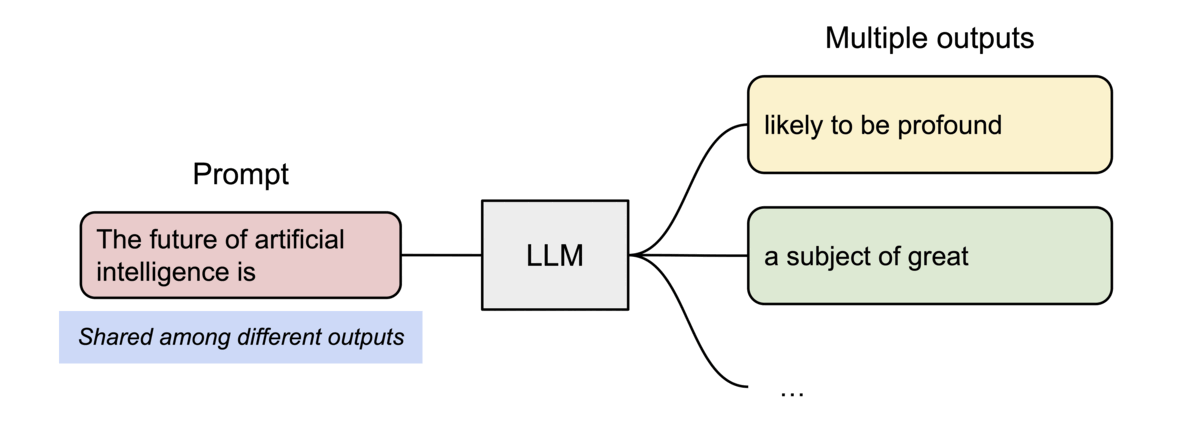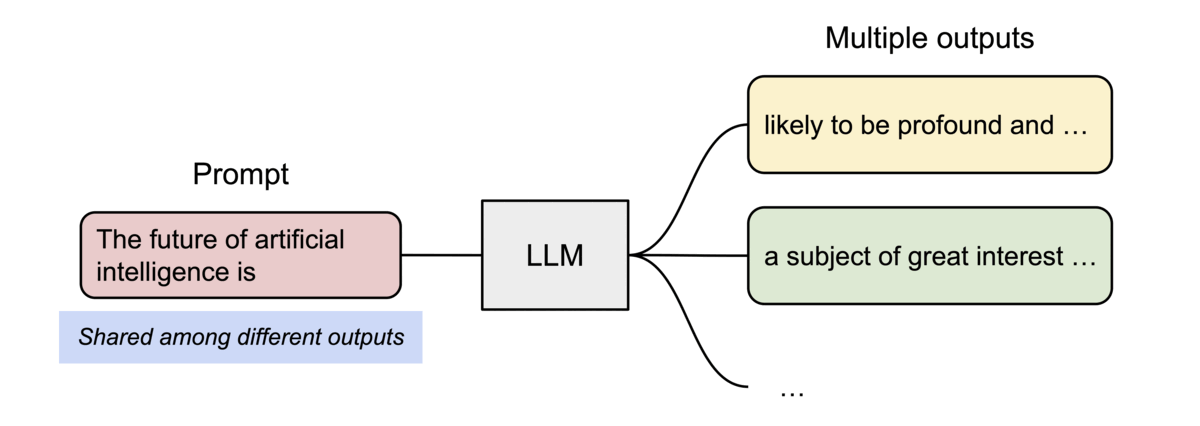
Figure 2: Parallel sampling in action. Multiple outputs share physical memory for the initial prompt.
- Inter-Request Sharing (Automatic Prefix Caching): Prefix Caching allows Request B to reuse memory from Request A. In multi-turn conversations or agentic workflows, different requests often share a common system prompt. vLLM caches these blocks across requests, significantly reducing “Time to First Token” (TTFT).
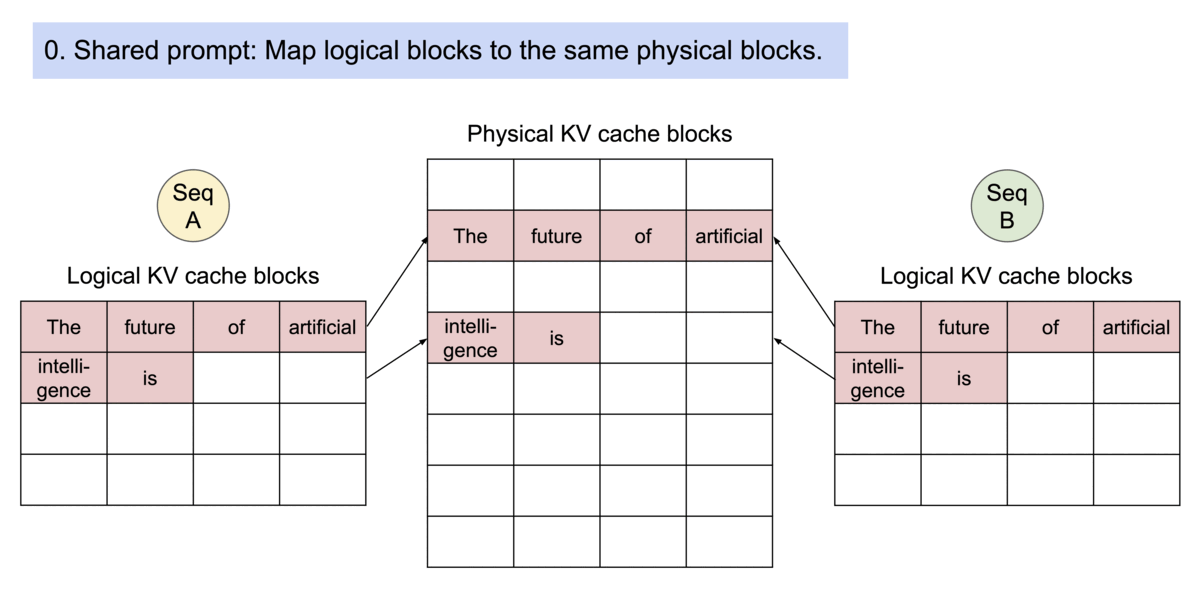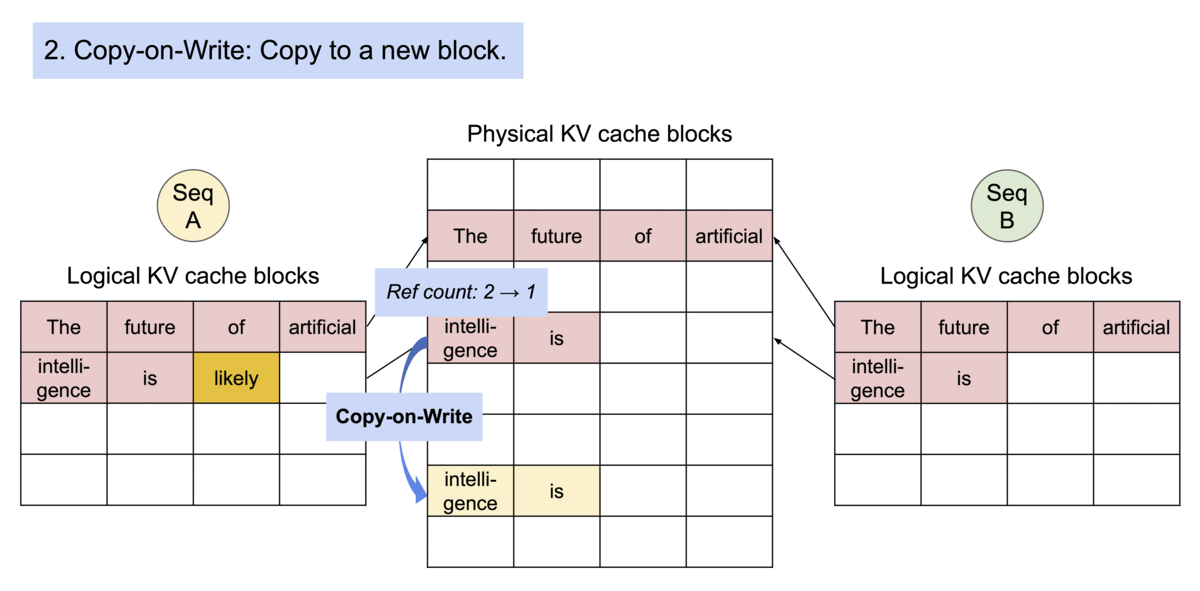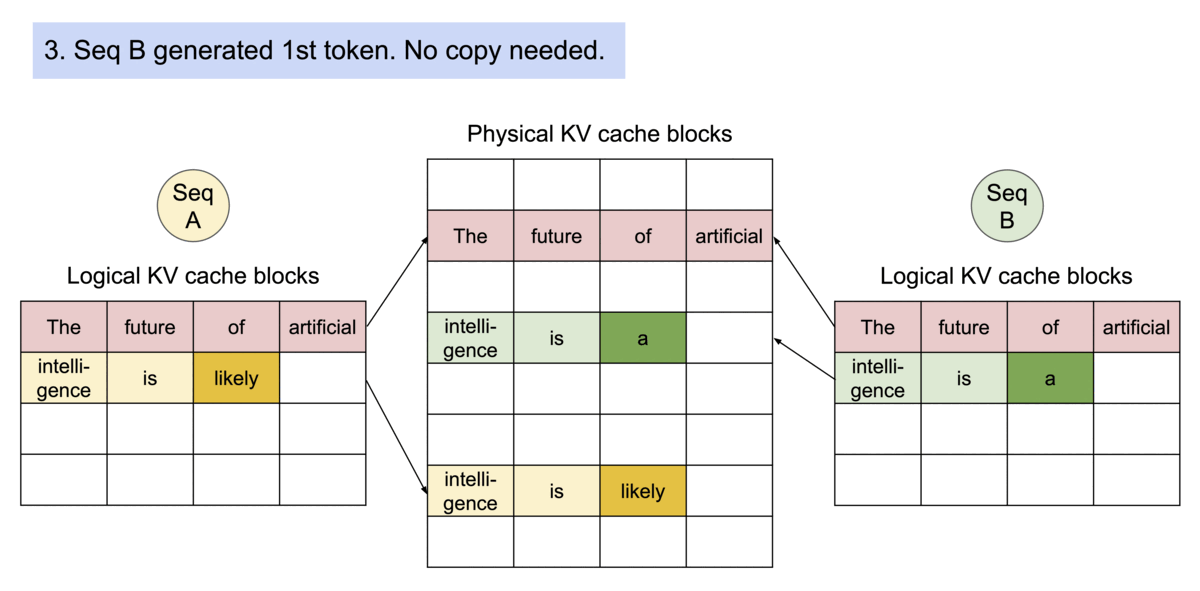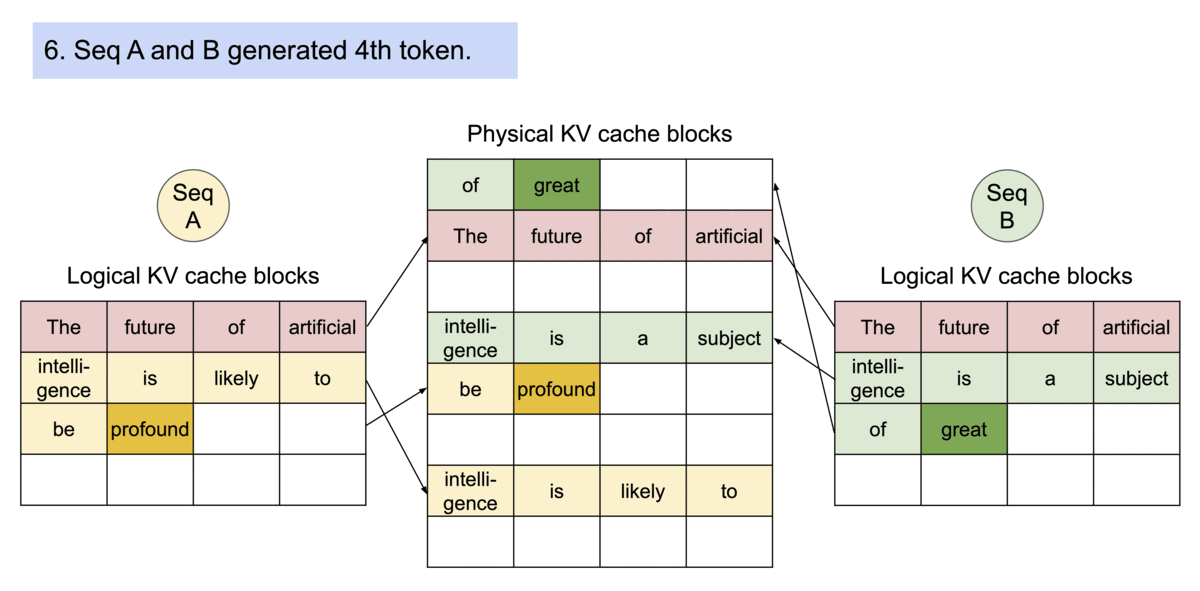
Figure 3: Shared Prefix Caching across independent requests.
3. Why Block Size Matters: Hardware and Model Nuances
The default block size in vLLM is 16 tokens, a choice driven by a trade-off between memory waste and hardware efficiency.
Hardware Constraints
- GPU Warp Alignment & Throughput: A Warp consists of 32 threads. In vLLM’s kernels, these threads fetch 16 Key and 16 Value vectors in a single coalesced memory transaction, fully saturating GPU bandwidth.
- The TensorRT-LLM Divergence: Enterprise engines like TensorRT-LLM often default to 64 or 128-token blocks 3. Larger blocks maximize throughput on H100s by reducing “indirection overhead” (fewer block table lookups) at the cost of higher fragmentation.
Model Architecture and Memory Variance
The “heaviness” of a block scales with the model’s dimensions. For example, at FP16 precision 4:
- Llama 3 8B: A 16-token block consumes ~1.0 MB.
- Llama 3 70B: A 16-token block consumes ~5.2 MB.
Modern architectures like DeepSeek-V3 use Multi-Head Latent Attention (MLA) to compress KV vectors, meaning 16 tokens can consume significantly less memory even at larger scales.
Formula for one vLLM block (16 tokens): \(\text{Bytes} = 16 \times \text{Layers} \times n_{KV\_heads} \times d_{head} \times \text{Precision\_Bytes} \times 2\)
4. Engineering the ‘Magic’: Production Implementation
The true production strength of vLLM lies in how it manages the gap between the CPU scheduler and the GPU kernels.
I. The CPU-GPU “Ping-Pong” Bottleneck
A subtle but critical nuance is the physical location of the metadata. The Block Table (logical mapping) resides on the CPU, while the KV Cache resides on the GPU.
- The Bottleneck: For every token generated, the CPU must determine the next physical block address and communicate it to the GPU. This Host-to-Device (H2D) communication can become a bottleneck for small, fast models where the GPU finishes a forward pass quicker than the CPU can schedule the next one.
- The Optimization: vLLM uses a highly optimized C++ scheduler to batch these mapping updates, but it places a high demand on the host’s single-core CPU performance.
II. CUDA Graph Replay and Padded Slots
Launching kernels for every token creates significant overhead. vLLM uses CUDA Graphs to “record” the sequence of kernel launches once, then “replay” them for every subsequent token without CPU-to-GPU roundtrips.
- Fixed Shapes: CUDA Graphs require static tensor shapes. vLLM captures graphs for specific power-of-two batch sizes (e.g., 1, 2, 4, 8, 16, 32…).
- The Padded Batch: If a batch contains 27 requests, it is padded to 32. The GPU computes all 32 slots, even if 5 are dummies.
- Continuous Batching Integration: This is where iteration-level scheduling shines. Slots in a CUDA Graph are not locked until the longest request finishes. As soon as a request hits an EOS token, the scheduler evicts it and slides a new request from the waiting queue into that exact “padded” slot for the very next replay, ensuring near-constant occupancy.
III. The “Swapping” Safety Valve
If VRAM is 100% full and a running request needs a new block, vLLM uses Swapping. It preempts the most recent request and moves its KV blocks from GPU VRAM to CPU RAM. This prevents Out-of-Memory (OOM) errors at the cost of a significant latency hit.
IV. Synergy with Speculative Decoding
In speculative decoding, a “draft” model predicts tokens that may be rejected by the “target” model. With PagedAttention, rejecting tokens is a simple metadata operation—unmapping physical blocks from the Block Table—rather than a costly memory re-alignment.
-
Kwon et al., “Efficient Memory Management for Large Language Model Serving with PagedAttention,” SOSP 2023. https://arxiv.org/abs/2309.06180 ↩ ↩2
-
“vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention,” vLLM Blog. https://vllm.ai/blog/vllm ↩ ↩2
-
NVIDIA, “TensorRT-LLM Documentation: KV Cache Management.” https://nvidia.github.io/TensorRT-LLM/latest/features/kvcache.html ↩
-
“Llama 3 Model Card and Performance Benchmarks,” Meta AI Research. https://github.com/meta-llama/llama3 ↩